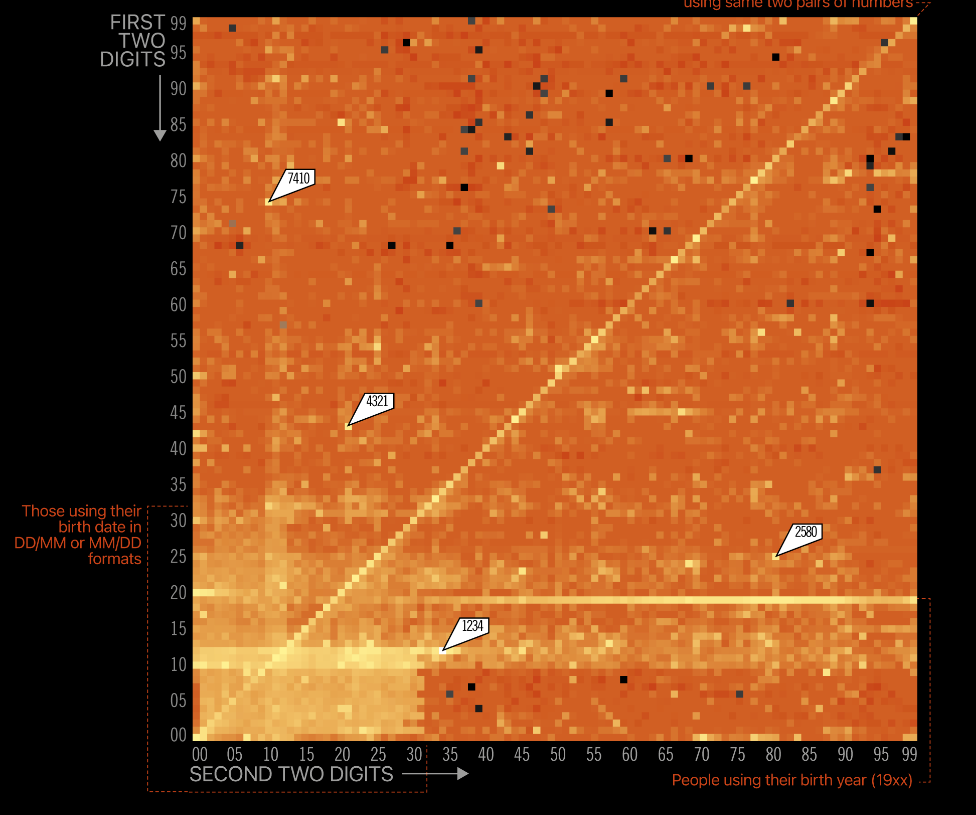
The power of a graph is amazing, even more in cybersecurity. You might have already seen this but it is still captivating: A visual representation of the frequency of 4 digits PIN codes.
It shows that 1234 & 4321 are still very frequent, so are pairs of the same two digits (like 0101 or 5566). Birthdate are still common too, of course.
Interesting fact: the 20 most frequent PIN Codes (0,2% of possibilities) represent 27% of all the used codes. So, if you use 1234, 4321, 0000, 7777, 2000, 2222, 9999, 5555 1122, 8888, 2001, 1111, 1212, 6969, 3333 or 6666, well, you making it quite easy to guess your PIN code.
Beautiful visualization from Information Is Beautiful
There is also a great analysis of the data used for this visualization on PIN number analysis (datagenetics.com)

You must be logged in to post a comment.