Here a our latest posts:
-
Is the “Genius Visa” USA’s secret weapon allowing them to win the AI race?
13 years ago, Pr. Michio Kaku, a renowned physicist, professor at Stanford, explained that USA’s secret weapon was “The genius visa” (H1-B), a Visa that allows exceptional scientists to migrate to the US. It’s the key to compensate for the failure of the American educational system. Is it also the case for AI? Dr Laurent…
-
Discover the Alarming Patterns of Common PIN Codes in a Striking Graph
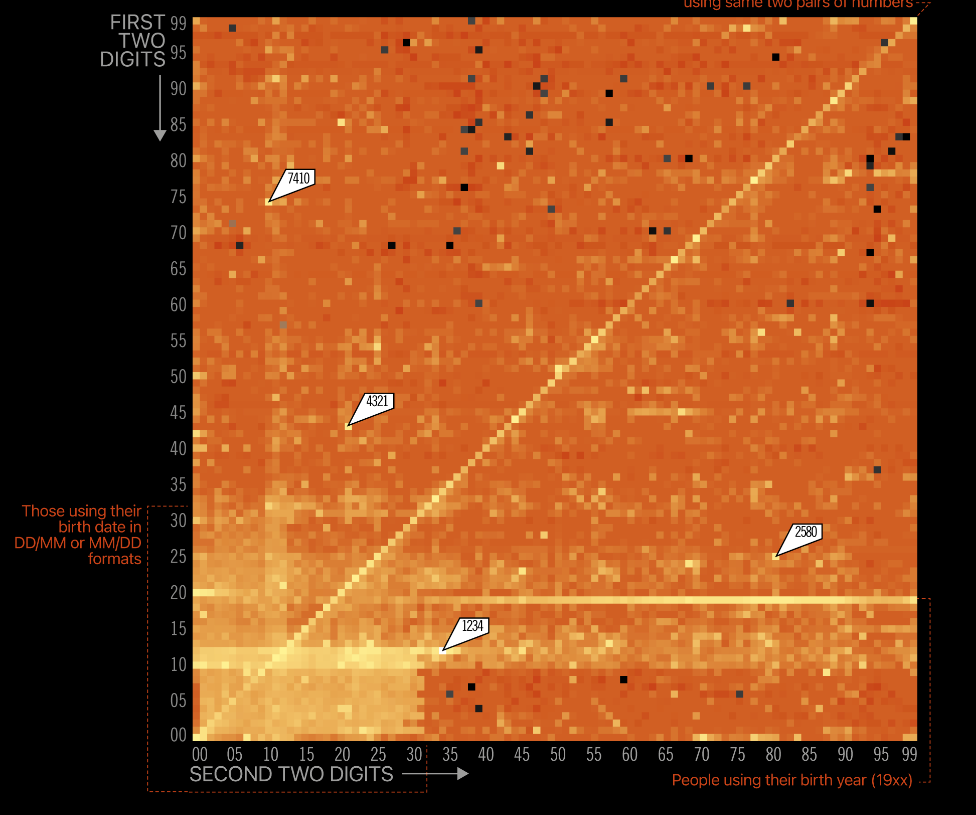
The power of a graph is amazing, even more in cybersecurity. You might have already seen this but it is still captivating: A visual representation of the frequency of 4 digits PIN codes. It shows that 1234 & 4321 are still very frequent, so are pairs of the same two digits (like 0101 or 5566).…
-
Password strength explained in one slide
Often we have to train people within a very limited timeframe. Here is an example on how to present examples of weak to strong passwords and also, foster the use of 2FA.
-
Training with images & videos? Yes, but good ones!
To improve our security and efficiency, we need well-trained people. It doesn’t have to be everything, but it should be enough to make their lives easier and/or safer. One of the difficulties nowadays is catching people’s attention, even at the office. Forget about long documents—maybe even short ones. When we, as people, want to learn…
-
The intention-behaviour gap in cybersecurity
More and more we see cybersecurity professionals using surveys about attitudes and intention as performance indicators of their interventions. While questions like “Do you think it is important to use complex passwords” might give an insight on someone’s attitude toward password complexity, they are not good indicators of our human-risks. Values, Attitudes, Intentions and Behaviours…
- Is the “Genius Visa” USA’s secret weapon allowing them to win the AI race?
- Discover the Alarming Patterns of Common PIN Codes in a Striking Graph
- Password strength explained in one slide
- Training with images & videos? Yes, but good ones!
- The intention-behaviour gap in cybersecurity
- The Consumer Authentication Strength Maturity Model (CASMM)
- Security Awareness Series from NCSA
- Is Security Awareness victim of the Shiny Object Syndrome?
- What would a cyber attack look like in the real world?
- Is computer-based training effective to prevent phishing?
- Is Punishment an effective deterrent for Phishing?
- Behavioural aspects of Cybersecurity: a systematic review
- Protection Motivation Theory (PMT)
- Video resources on Cyber Security Awareness
- If there was only one, what would be the security behaviour change you’d like to see?
- How do penalties affect your security policies effectiveness?
- User-Interface design: an overlooked security matter
- Improving security culture by stopping toxic behaviours
- Phishing: KPI or KRI?
- Phishing: KPI or KRI?
- Click ratio is a useless metric for phishing!
- A funnier way to test passwords
- Free webinars on CyberSecurity for Small & Medium Businesses
- Do we get enough “soft skills” training in (CyberSecurity) our curricula?
- Emergency numbers were down in Belgium. Be-Alert warned us and might have already saved people.
- Improving security culture by stopping toxic behaviours
- User-Interface design: an overlooked security matter
- The impact of cyber crime on Belgian Businesses
- You receive spam by SMS (or via email) in Belgium, you can report it online to the authorities!
- Risk management as a decision tool: a synthetic diagram
- If there was only one, what would be the security behaviour change you’d like to see?
- Are you prepared to face a TDOS?
- How do penalties affect your security policies effectiveness?
- StartSSL is blocked by Chrome & Firefox and they didn’t notified their customers
- No Wifi in the Airport? Use the Searchable Airport Wi-Fi Database
- Your security maturity is low? Are you using your people the best way you can?
- Fappening 2.0: You should mind who you trust!
- No, a virtual machine is not as safe as a physical one!
- We need more (security) fixers!
- With the US judge ruling against Google, will GDPR force European companies to leave the cloud?
- Why is usability important for security management?
- SMS spammers 1 – belgium: 00
- Will IoT kill us someday?
- Should companies create Bitcoin accounts to be ready to pay ransoms?
- Your phishing awareness campaign may do more harm than good
- Is Cybersecurity a good buzzword?
- Improve and speed up your Firewall Change Requests management for free
- Ooops, they did it again! Was my password compromised, again?
- Red team exercises are like vaccination against attacks?
- Victim of a ransomware? Call the Crypto Sheriff!
- To protect against quantum computers, will we have quantum teleportation?
- 9 tips to improve the security of your web applications
- Google (also) knows what you said last summer
- Sauron, an APT created by a government?
- How to detect fake or stolen IDs?
- Blockbusters, a new risk to add to our threats’ list?
- Are Red Team exercises close enough to reality?
- Security: It’s all about trust!
- Anatomy of an URL: The cheat sheet
- 1 Fortune 500 out of 3 hasn’t define SPF for its email communications
- Cost effective One-Time Password solution: How to install yubico’s plugin on Freeradius
- The belgian ministry of defence recruits 24 cyber security specialists.
- Crime-as-a-Service, the new emerging model of a 300+ billion$ business?
- Google knows what you did last summer!
- Setup a proxy server on a Synology
- Effective security management: 20 tips to change your audience’s behaviour
- The lost meaning of our (professional) life
- Even if you are good at what you do, you may get a job…or not!
- Is happiness at work a security concern?
- Information classification: practical guidelines
- Information classification for dummies
- Pets at work to reduce stress
- Altruism is contagious and might bring you happiness
- The way to success… is not that straight!
- Who don’t need arbejdsglaede?
- No training is (often) bad training
- Training your employees
- Information Security Awareness – Passwords
- Improved communication
- What motivates us?
- Why happiness is good for business
- Pursuit of Perfect
- Happiness at work, a path to success
- Delivering happiness
- ReWork
- Great (Human) Leadership
- The right to be wrong